| 深入理解Spring注解机制:注解的搜索与处理机制 | 您所在的位置:网站首页 › spring 的注解 › 深入理解Spring注解机制:注解的搜索与处理机制 |
深入理解Spring注解机制:注解的搜索与处理机制
|
前言 众所周知,spring 从 2.5 版本以后开始支持使用注解代替繁琐的 xml 配置,到了 springboot 更是全面拥抱了注解式配置。平时在使用的时候,点开一些常见的等注解,会发现往往在一个注解上总会出现一些其他的注解,比如 @Service: @Target({ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) @Documented @Component // @Component public @interface Service { @AliasFor(annotation = Component.class) String value() default ""; }大部分情况下,我们可以将 @Service 注解等同于 @Component 注解使用,则是因为 spring 基于其 JDK 对元注解的机制进行了扩展。 在 java 中,元注解是指可以注解在其他注解上的注解,spring 中通过对这个机制进行了扩展,实现了一些原生 JDK 不支持的功能,比如允许在注解中让两个属性互为别名,或者将一个带有元注解的子注解直接作为元注解看待,或者在这个基础上,通过 @AliasFor 或者同名策略让子注解的值覆盖元注解的值。 本文将基于 spring 源码 5.2.x 分支,解析 spring 如何实现这套功能的。 一、层级结构当我们点开 Spring 提供两个注解工具类 AnnotationUtils 或者 AnnotatedElementUtils 时,我们可以从类注释上了解到,Spring 支持 find 和 get 开头的两类方法: get :指从 AnnotatedElement 上寻找直接声明的注解;find:指从 AnnotatedElement 的层级结构(类或方法)上寻找存在的注解;大部分情况下,get 开头的方法与 AnnotatedElement 本身直接提供的方法效果一致,比较特殊的 find 开头的方法,此类方法会从AnnotatedElement 的层级结构中寻找存在的注解,关于“层级结构”,Spring 给出了一套定义: 当 AnnotatedElement 是 Class 时:层级结构指类本身,以及类和它的父类,父接口,以及父类的父类,父类的父接口......整个继承树中的所有 Class 文件;当 AnnotatedElement 是 Method 是:层级结构指方法本身,以及声明该方法的类它的父类,父接口,以及父类的父类,父类的父接口......整个继承树中所有 Class 文件中,那些与搜索的 Method 具有完全相同签名的方法;当 AnnotatedElement 不是上述两者中的一种时,它没有层级结构,搜索将仅限于 AnnotatedElement 这个对象本身;举个例子,假设我们现在有如下结构: 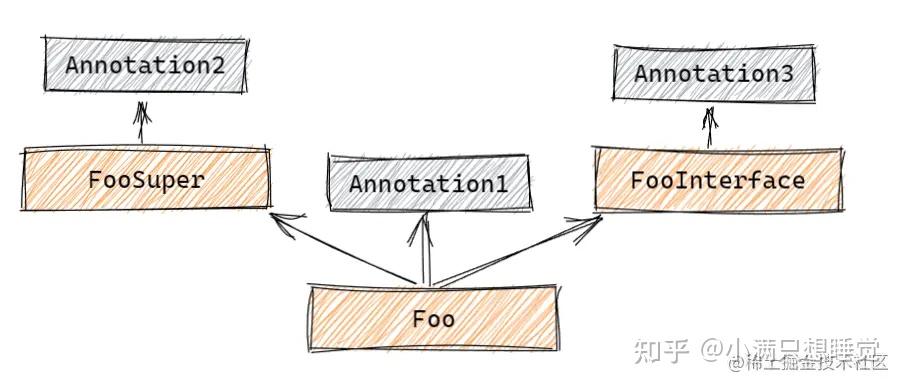 则对 Foo.class 使用 get 开头的方法,或者 AnnotatedElement 本身提供的方法,都只能获得 Annotation1,而使用 find 方法除了可以获得 Foo 本身的注解,还可以获得 FooSuper 和 FooInterface 上的注解。 同理,假如我们扫描的是 Foo.class 中一个名为 foo,没有参数且没有返回值的方法,则 find 除了扫描 Foo.foo() 外,还会扫描器 FooSuper 和 FooInterface 中没有参数且没有返回值的方法上的注解。 二、合并注解当我们点开 Spring 提供两个注解工具类 AnnotationUtils 或者 AnnotatedElementUtils 时,我们可以从类注释上了解到,Spring 支持 find 和 get 开头的两类方法: public static A findAnnotation(Method method, @Nullable Class annotationType) { if (annotationType == null) { return null; } // 如果不需要对层级结构进行搜索也能找到注解 if (AnnotationFilter.PLAIN.matches(annotationType) || AnnotationsScanner.hasPlainJavaAnnotationsOnly(method)) { return method.getDeclaredAnnotation(annotationType); } // 注解无法直接获取,需要对层级结构进行搜索 return MergedAnnotations.from(method, SearchStrategy.TYPE_HIERARCHY, RepeatableContainers.none()) .get(annotationType).withNonMergedAttributes() .synthesize(MergedAnnotation::isPresent).orElse(null); }这个方法很清晰地描述了一个注解的查找流程: 先对 AnnotatedElement 本身进行查找,并且使用注解过滤器 AnnotationFilter 进行处理; 找不到再通过一个叫 MergedAnnotations 的东西对 AnnotatedElement 进行查找,这玩意需要指定三个东西: 查找的 AnnotatedElement; 搜索策略 SearchStrategy; 可重复注解容器 RepeatableContainers; 可见,真正的搜索过程发生在合并注解 MergedAnnotations。 1、注解过滤器 其中,AnnotationFilter 是我们见到的第一个组件。该类是一个函数式接口,用于匹配传入的注解实例、类型或名称。 @FunctionalInterface public interface AnnotationFilter { // 根据实例匹配 default boolean matches(Annotation annotation) { return matches(annotation.annotationType()); } // 根据类型匹配 default boolean matches(Class type) { return matches(type.getName()); } // 根据名称匹配 boolean matches(String typeName); }AnnotationFilter默认提供三个可选的静态实例: PLAIN:类是否属于 java.lang、org.springframework.lang 包;JAVA:类是否属于 java、javax包;ALL:任何类;此处过滤器选择了 PLAIN,即当查找的注解属于 java.lang、org.springframework.lang 包的时候就不进行查找,而是直接从被查找的元素直接声明的注解中获取。这个选择不难理解,java.lang包下提供的都是诸如@Resource或者 @Target 这样的注解,而springframework.lang包下提供的则都是 @Nonnull 这样的注解,这些注解基本不可能作为有特殊业务意义的元注解使用,因此默认忽略也是合理的。 实际上,PLAIN 也是大部分情况下的使用的默认过滤器。 2、合并注解当对 AnnotatedElement 直接搜索无法获得符合条件的注解时,Spring 就会尝试通过 MergedAnnotations 对层级结构进行搜索,并对获得的注解进行聚合。在这个过程中,被聚合的注解就会被封装为 MergedAnnotation,而结束搜索后,获得的全部 MergedAnnotation 又会被聚合为 MergedAnnotations。 MergedAnnotation MergedAnnotation 直译叫合并注解,MergedAnnotation 通常与一个注解对象一对一,但是它的属性可能来自于子注解或者元注解,甚至是同一个注解中通过 @AliasFor 绑定其他属性,因此称为“合并”注解——这里的合并指的是属性上的合并。 MergedAnnotations 而 MergedAnnotations 则用于提供一个基于 AnnotatedElement 快速扫描并创建一组 MergedAnnotation 的功能,在AnnotationUtils.findAnnotation 中,使用了 MergedAnnotations.from 方法创建一个 TypeMappedAnnotations 实现类: static MergedAnnotations from(AnnotatedElement element, SearchStrategy searchStrategy, RepeatableContainers repeatableContainers) { // 3、过滤属于`java`、`javax`或者`org.springframework.lang`包的注解 return from(element, searchStrategy, repeatableContainers, AnnotationFilter.PLAIN); } static MergedAnnotations from(AnnotatedElement element, SearchStrategy searchStrategy, RepeatableContainers repeatableContainers, AnnotationFilter annotationFilter) { Assert.notNull(repeatableContainers, "RepeatableContainers must not be null"); Assert.notNull(annotationFilter, "AnnotationFilter must not be null"); return TypeMappedAnnotations.from(element, searchStrategy, repeatableContainers, annotationFilter); }具体细节我们我们先不看,光看最后调用的方法,我们知道 MergedAnnotations 的创建需要四样东西: 查找的 AnnotatedElement;搜索策略 SearchStrategy;可重复注解容器 RepeatableContainers;注解过滤器 AnnotationFilter; 二、注解的搜索当 MergedAnnotations 被创建后,并不会立刻就触发对 AnnotatedElement 的搜索,而是等到调用 MergedAnnotations.get 时才开始,我们以 TypeMappedAnnotations 为例: public MergedAnnotation get(Class annotationType, @Nullable Predicate |
【本文地址】